What is web crawling? How to apply? Practical case teaching
Time: 2024-04-26 10:18 Click:
In today's digital era, data is like the bright stars in the vast sky, becoming the core driving force for enterprises to overcome obstacles in the market. Web crawling is like a dexterous spaceship that shuttles between the stars of data, opening up a convenient way for enterprises to obtain precious information. Web crawling empowers businesses to make more changes in a data-driven way. Smart business decisions. But what exactly is web crawling, how is it used, and how to crawl web pages?
What is web scraping?

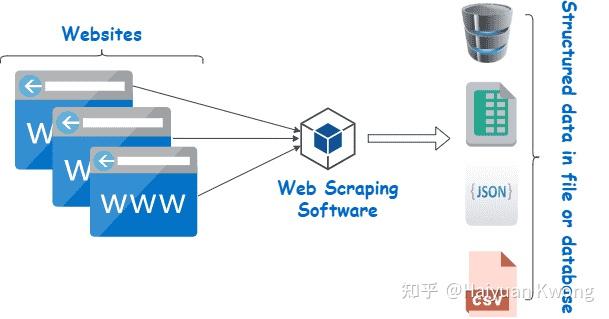
Web scraping is essentially the wonderful process of accurately extracting and analyzing data in the vast world of the Internet with the help of automated tools. These tools have keen insights and can quickly identify and capture the information treasures that enterprises urgently need. The captured data provides enterprises with rich and detailed market insights and decision-making basis. The implementation of this technology often relies on various web scraping tools and scripts that simulate the behavior of humans browsing the web, but perform at a faster speed and at a larger scale. These tools can parse the HTML code of web pages, CSV tables and JSON documents, and can be used according to user needs to extract the required data, including text, images, dates, links, videos and comments, and save it in a database or file in for further analysis and use.
So, in what directions can web scraping be applied?
First, gain insight into market dynamics.
Web crawling enables companies to grasp market trends in real time, including key information such as changes in competitors' price strategies and product iterations. Through in-depth research and analysis of these data, companies can promptly adjust their market strategies and remain invincible in the fierce competition.
Second, tap potential customers.
Web scraping is like a master key that can help companies filter out potential customer groups from the massive information on the Internet. With the help of precise analysis of user behavior data, interests and hobbies, companies can more accurately locate target customers, thereby improving the effectiveness and accuracy of marketing.
Third, social media monitoring
In the vast arena of social media, web scraping plays a vital role. Web scraping research can monitor important information such as brand reputation evaluations on social media and user feedback in real time, allowing companies to gain timely insight into market dynamics, flexibly adjust product strategies, and enhance the brand's image and reputation.
Fourth, stimulate content innovation
Web scraping is not only a collector of data, but also a treasure trove of inspiration for content innovation. By capturing hot topics, popular trends and other information on the Internet, companies can create content that is more in line with user needs and more attractive, thereby increasing the dissemination and influence of the content.
Fifth, gain insight into user emotions
Web scraping can deeply analyze users’ comments on social media, forums and other platforms, revealing users’ emotional tendencies and true views of the brand. This helps companies discover problems in a timely manner, solve hidden dangers, maintain the reputation of the brand, and enhance customer trust.
Sixth, image recognition.
Web crawling technology can not only process text data, but also capture and analyze multimedia data such as images and videos. By capturing and researching product pictures on the Internet, companies can analyze product styles, colors and other characteristics to provide strong support for product innovation.
Seventh, risk management.
In the field of risk management, web scraping also plays an indispensable role. By capturing and analyzing various types of risk-related information, companies can provide early warning of potential risks, formulate scientific and effective countermeasures, and reduce business risks. In addition, web scraping can also help companies predict market trends and provide a solid and reliable basis for strategic decisions.
Is web scraping legal?
Check the website's "robots.txt" to see if they allow web scraping. You can easily find this file by typing "/robots.txt" at the end of the website URL. If you want to crawl the Amazon website, you can check out the www.amazon.com/robots.txt file. Now, look at the "allowed" and "disallowed" paths to understand what the website spider may or may not allow you to access from the page source of the crawled item.
What are the difficulties faced in web crawling?
First, the learning curve is long. Although web scraping tools can simplify the process of collecting data from the web to some extent, realizing their full potential can take a while to learn and master.
Second, the layout and structure of the website are subject to change. There are many subtleties and nuances in the process of building a website. In order to obtain a better user experience, web designers will constantly update the website. Even the smallest changes can mess up the data collected.
Third, complex websites require more advanced crawling technology. Obtaining data from sites with features such as dynamic elements and infinite scrolling may require more advanced skills.
Fourth, strict website terms and conditions. In addition to technical barriers, some sites have guidelines for using data and content that prohibit web scraping. This is often the case especially for websites that use proprietary algorithms. To protect their content, these sites may use encoding that makes web scraping nearly impossible.
Unblock web scraping with anti-detection browsers
As mentioned before, when performing web scraping operations, especially when large amounts of data need to be crawled, or data is scraped from sites with strict anti-crawling policies, it is highly possible to use regular crawlers. There is a risk of being detected and blocked.
Websites will use a variety of methods to detect crawler behavior, such as checking the user agent information in the HTTP request header, monitoring abnormal access patterns from the same IP address, or using more advanced technology to analyze browser fingerprints. Once crawling behavior is detected, the website may block the corresponding IP address or take other measures to limit data crawling.
In this case, anti-detection of the browser is crucial. There is a close connection between web scraping and anti-browser detection, mainly reflected in the need for privacy protection and countering anti-crawler strategies. Because anti-detection browsers can help us hide our identity, avoid the website's identification and blocking of crawler behavior, and thus complete the data crawling task more efficiently.
BitBrowser - Web scraping utility tool
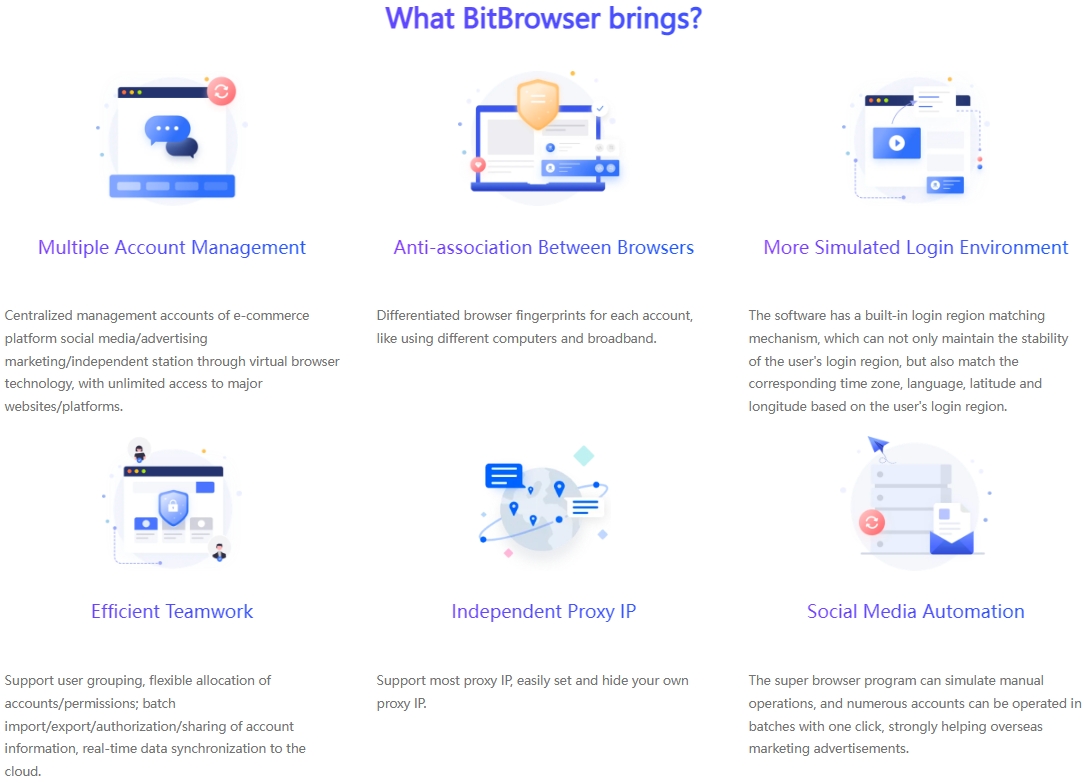
Through BitBrowser, you can:
Create an independent browsing environment network so that you can perform web scraping tasks more efficiently.
Manage workflow and protect the privacy of browser fingerprint parameters to websites, making the crawling process more secure.
Using virtual profiles that consume fewer resources to perform faster crawling tasks can help you complete crawling tasks in a fraction of the time.
Set different geolocations for different profiles. This allows you to simulate different users from different locations to verify the effectiveness of your ad placements.
With browser automation enabled, if you need to perform repetitive tasks, you can automate them, therefore, you can save time and resources and focus on other key aspects of your business.
Summarize:
With the rapid development of Internet technology, web crawling has continued to develop and evolve, and has gradually become one of the indispensable key technologies in e-commerce and many other industries. It can be said that web scraping is a complex and valuable field. It requires not only solid technical knowledge, but also careful planning and appropriate tools to support it. Through the proper use of anti-browser detection and other scraping technologies, developers and data analysts can fully tap into the rich information resources of the web, thereby bringing deep insights and significant competitive advantages to the business. Now click to visit the BitBrowser website and start trying to crawl the web.